Unlock the power of AI in your business with our AI Opportunity Identification Framework. Learn how to systematically identify, evaluate, and prioritize AI applications that deliver real value.
Information bombards us from every angle, making the ability to discern fact from fiction crucial. With 75% of adults falling for fake news, data literacy emerges as our compass in the digital landscape. Learn how critical thinking can combat clickbait culture and empower informed decision-making.
Empower your career with the knowledge and tools to make data-informed decisions. Explore our articles, assessments, job aides, white papers, learning videos, data literacy GPT, expert-led consulting services, and much more. Click to discover how data can drive your success.
In the world of statistics and probability, there are several fundamental concepts that help us make sense of the seemingly random events around us. One such concept is the Law of Large Numbers, a powerful idea that has far-reaching implications in various fields, from finance and economics to psychology and social sciences.
What is the Law of Large Numbers?
The Law of Large Numbers, in its simplest form, states that as the number of trials or observations increases, the average of the results will converge towards the expected value. In other words, the more times you repeat an experiment or observe an event, the closer the average outcome will be to the true probability of that event occurring.
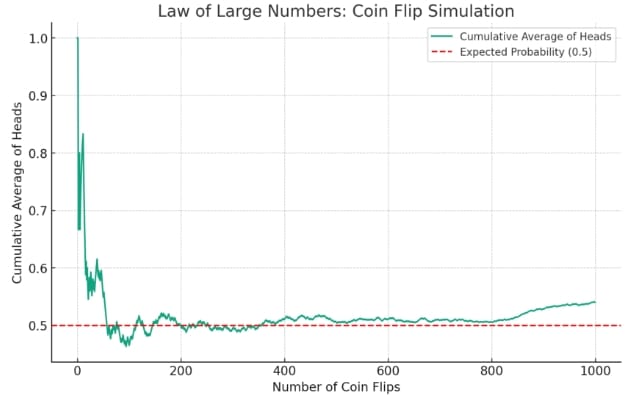
To illustrate this, let's consider a simple example: flipping a fair coin. We know that a fair coin has a 50% chance of landing on heads and a 50% chance of landing on tails. If you flip the coin just a few times, you might get a sequence of results that doesn't seem to reflect these probabilities. For instance, you might get three heads in a row. However, as you continue to flip the coin more and more times, the proportion of heads and tails will start to even out, gradually approaching the expected 50-50 split.
The Importance of Sample Size
The Law of Large Numbers highlights the importance of sample size in statistical analysis. When dealing with a small number of observations, the results can be heavily influenced by random fluctuations and may not accurately represent the true nature of the phenomenon being studied. As the sample size increases, these random fluctuations tend to cancel each other out, revealing the underlying patterns or trends.
This is why surveys and polls often require a large number of participants to produce reliable results. A survey with only a handful of respondents might yield vastly different conclusions compared to one with thousands of participants. The larger the sample size, the more confident we can be that the results are representative of the population as a whole.
Real-World Applications
The Law of Large Numbers has numerous applications in various fields. Let's explore a few examples:
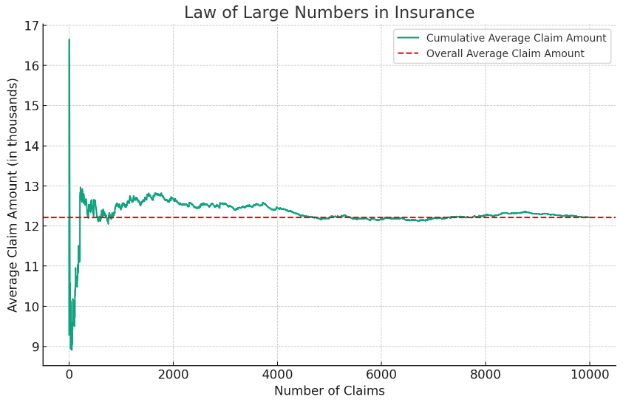
Insurance. Insurance companies rely on the Law of Large Numbers to set premiums and manage risk. By analyzing large datasets of past claims and events, insurers can estimate the likelihood of certain events occurring and adjust their prices accordingly. While individual claims may vary significantly, the average claim amount tends to be predictable when considering a large enough pool of policyholders.
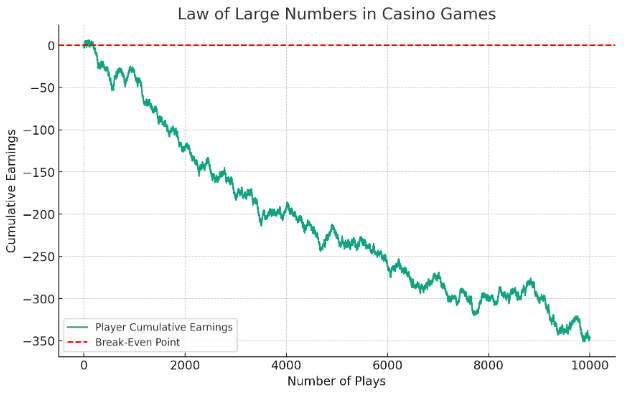
Casino Games. The Law of Large Numbers is the reason why casinos always have an edge over players in the long run. While a player might experience short-term wins or losses, the house advantage ensures that the casino will come out ahead over a large number of plays. This is why it's important for players to understand that the odds are always in favor of the house, regardless of any short-term successes.
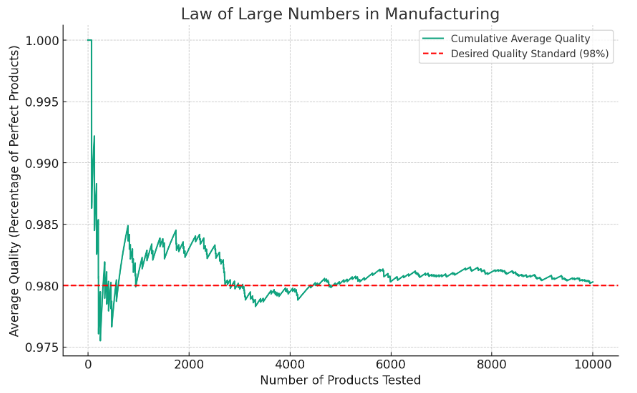
Quality Control. Manufacturers use the Law of Large Numbers to ensure the consistency and reliability of their products. By testing a large number of items from a production line, they can identify and correct any defects or variations. The average quality of the products will tend to converge towards the desired standard as the sample size increases.
Limitations and Misconceptions
While the Law of Large Numbers is a powerful concept, it's important to understand its limitations and avoid common misconceptions.
One misconception is the belief that the Law of Large Numbers guarantees that an event will occur a specific number of times in a large number of trials. For example, some might mistakenly believe that flipping a fair coin 1,000 times will always result in exactly 500 heads and 500 tails. However, the Law of Large Numbers only suggests that the proportion of heads and tails will approach 50-50 as the number of flips increases, not that it will be a perfect split.
Another limitation is that the Law of Large Numbers does not apply to all types of events or phenomena. It works best for independent, random events with a fixed probability. In real-life situations, many factors can influence the outcome of an event, and the assumptions of independence and fixed probabilities may not hold true. For example, if you're studying the success rate of a new medical treatment, the outcomes for individual patients may not be independent because factors such as age, overall health, and genetics can influence the effectiveness of the treatment. Additionally, the probability of success might not be fixed, as the treatment could become more effective over time as doctors gain experience with it. In such cases, the Law of Large Numbers may not provide an accurate prediction of the long-term success rate of the treatment.
Calculating the Required Sample Size
To determine the number of samples needed to predict the average with a desired level of accuracy, you can use the concept of the margin of error and the sample size formula. The margin of error is the maximum expected difference between the true population mean and the sample mean.
The sample size formula is:
n = (Z^2 * σ^2) / E^2
Where:
n is the sample size
Z is the Z-score (related to the confidence level)
σ is the population standard deviation
E is the margin of error
To use this formula, follow these steps:
Determine the desired confidence level (e.g., 95%) and find the corresponding Z-score. For a 95% confidence level, the Z-score is 1.96.
Estimate the population standard deviation (σ). If unknown, you can use a sample standard deviation from a pilot study or previous research.
Decide on the acceptable margin of error (E). This is the maximum difference you are willing to accept between the sample mean and the true population mean.
Plug these values into the formula and solve for n.
For example, suppose you want to estimate the average height of students in a university with a 95% confidence level and a margin of error of 2 cm. From a previous study, you know that the standard deviation of heights is approximately 10 cm. Using the formula:
n = (1.96^2 * 10^2) / 2^2 = 96.04
Rounding up, you would need a sample size of at least 97 students to achieve the desired level of accuracy.
Keep in mind that this formula assumes a simple random sampling method and a large enough population to justify using the Z-distribution. For smaller populations or different sampling methods, additional factors may need to be considered.
Are You Data Literate?
Becoming data literate begins in your inbox. Sign up to receive expert guidance, news, and other insights on the topics of data literacy and data-informed decision-making. Want to know more about our mission? Visit our About Page. Thanks for visiting!